Control Structures
In this chapter we introduce the various commands that Tcl includes for controlling how the program executes. These include conditional branches for making decisions, loops for counting and iterating over data structures, constructs for dealing with error conditions, and procedures for creating new commands.
3.1 Branching with if and switch
3.1.1 The if Command
Like most languages, Tcl supports an if command for branching based on a simple Boolean condition. The syntax is as follows:
| if cond ?then? body1 ?elseif cond2 body2 ...? ?else bodyN? |
if {$x < 0} {
puts "$x is negative"
} elseif {$x > 0} {
puts "$x is positive"
} else {
puts "$x is zero"
}
The test expression should return a value that can be interpreted as representing ‘true’ or ‘false’. Valid Boolean values are shown in Table 2. The string constants ‘yes’/‘no’ and ‘true’/‘false’ are case-insensitive, so ‘True’ and ‘FALSE’ and ‘YeS’ etc. are all valid truth values. If the test condition expression evaluates to true then body1 is executed, otherwise any further conditional checks, specified in elseif clauses are tested in turn. Finally, if no conditional expression evaluates to true, then the final body following an else clause is executed (if supplied). All test expressions are evaluated in the same manner as the expr command, discussed in Section 1.5. Each body is an arbitrary Tcl script (sequence of commands separated by newlines or semi-colons). As for expr, it is good style to surround all test expressions with braces. The if command returns the result of the last command executed in the selected code body, or the empty string if no condition matched (and no else clause was supplied).
3.1.2 The switch Command
An alternative to a long sequence of if/elseif/else branches is to use the switch command. Tcl’s switch is similar to the switch statements found in languages such as C or Java, except that it allows switching on arbitrary strings rather than just integers and builds in some sophisticated pattern matching machinery. The switch command matches a value against a list of patterns; the first pattern that matches the value is chosen and an associated code body is executed. A switch command can often be easier to read than a long if command, but is more restricted in the types of conditions it can match. The syntax of the command takes one of two forms:
|
switch ?options? value pattern1 body1 ?pattern2 body2? ...?patternN bodyN? — or — switch ?options? value { pattern1 body1 ?pattern2 body2? ...?patternN bodyN? } |
# Use the same branch body for multiple conditions
switch $x {
0 - 1 - 2 -
3 { puts "$x is between 0 and 3" }
default { puts "$x > 3 or $x < 0" }
}
By default, Tcl uses exact string matching when determining which pattern matches the input value1. A number of options can be given to the switch command to change the matching process:
- -exact
- Use exact string matching (the default).
- -glob
- Use ‘glob-style’ pattern matching (see Section 2.1).
- -regexp
- Use regular-expression pattern matching (see Section 2.6).
- -nocase
- Use case-insensitive matching.
- –
- Indicates ‘end of options’, and should always be specified if the value being matched may start with a dash.
A handful of other options can also be specified to further control the matching process. These are listed in the switch manual page [10].
3.2 Loops: while and for
Tcl includes two general commands for looping, the while and for commands. Both of these commands implement imperative loops, as found in languages such as C or Java. That is, these loops work by making updates to some state at each iteration until some termination condition has been satisfied. In addition to the general looping commands, Tcl also has a number of specialised loop commands, such as foreach, which loop over the elements of a particular collection, e.g., a list. The foreach loop is discussed in Section 3.2.4, while other loops are introduced elsewhere in the book.
3.2.1 The while Loop
The while command evaluates a script repeatedly while some condition remains true. The syntax of the command is as follows:
| while test body |
The test argument is an expression, in the same format as for expr (see Section 1.5), which must evaluate to a Boolean value. If the test evaluates to true, then the body script is executed, and then the loop is repeated. If the test evaluates to false, then the loop terminates and control moves on to the next command in the program. For example, we can use a while loop to count from 1 to 102:
set i 1
while {$i <= 10} {
puts "i = $i"
incr i
}
puts "Done!"
It is important to note that changes made to variables within the loop persist once the loop has terminated. In this case, the variable i will be set to 10 after the loop has finished. If the test condition evaluates to false when the while loop is first executed, then the body is never executed, as in this example:
set x "no"
if {$x} { puts "Cannot happen!" }
The test condition to while must be placed within braces. The reason for this is that the while command, like every statement in Tcl, is just another command and the same syntax rules apply. In particular, only a single round of substitution is done on the command, If braces were not used then Tcl would substitute the current values for any variables in the expression when the command is originally called, and these would then never be updated, resulting in the test condition never evaluating to false, which would then cause an infinite loop.
3.2.2 The for Loop
Tcl supports an iterated loop construct similar to the for loop found in C or Java. The for command in Tcl takes four arguments: an initialisation, a test, a ‘next’ script, and the body of code to evaluate on each pass through the loop:
| for init test next body |
Evaluate the init script.
Evaluate the test expression: if false then terminate; otherwise continue.
Evaluate the loop body script.
Evaluate the next script.
Go to step 2.
By including init and next arguments, the for loop helps to separate those parts of the code that are part of the application logic (i.e., everything in the loop body), from those parts that are just there to control the loop. Compare the following for loop for counting from 1 to 10 to the example shown in Section 3.2.1:
for {set i 1} {$i <= 10} {incr i} {
puts "i = $i"
}
puts "Done!"
Notice how all references to the loop variable, i are now entirely contained within the for loop, and clearly separated from the loop body. Please note, though, that this does not mean that the scope of the i variable is confined to the loop. In fact, like a while loop, the variable will still exist after the loop with the value it was last assigned (10 in this case).
The init and next arguments can contain arbitrary Tcl scripts. In particular, you can initialise and update multiple loop variables in these scripts, or perform other resource initialisation. For instance, here is a program to display all the lines in a text file3 with line numbers:
for {set i 1; set in [open myfile.txt]} {[gets $in line] != -1} {incr i} {
puts "$i: $line"
}
close $in
While such code is possible, it is not always a good idea. In this example, for instance, the test expression is also being used to actually read a line of the file into the line variable, which may not be immediately obvious to a reader of this code. The choice of when to use a for loop and when to use a plain while loop is largely one of determining which form is most readable. If your loop can be cleanly broken into initialisation, iteration, and test invariants, then a for loop can be a good choice, otherwise a while loop may be clearer. Ultimately, what matters most is whether the resulting code is understandable to somebody reading it later.
As for the while loop, the test expression should always be enclosed in braces. It is good style to also enclose the other arguments in braces.
3.2.3 Early termination: break and continue
Sometimes even the for command is not flexible enough to accurately capture all the termination and iteration conditions of your loop (i.e., when to stop and when to start the next cycle through the loop). Tcl provides two further commands that can be used with for and while to allow finer control over these conditions: the break and continue commands. These commands can be used within the loop body, and when encountered, they cause the loop to stop processing that iteration and to perform a special action:
- break:
- Causes the loop to terminate completely.
- continue:
- Causes the loop to stop this iteration and begin on the next.
The continue command essentially just ends the current loop iteration early. Any test conditions and next steps are still evaluated before the next iteration. The break command stops the loop altogether. One common use of these commands is to code apparently infinite loops, in which the termination condition is actually hidden within the body of the loop. Here is an example, in which we want to read user input until they enter a special ‘quit’ message:
# An infinite loop
while 1 {
set input [gets stdin]
if {$input eq "quit"} { break }
puts "You said: $input"
}
puts "Goodbye!"
Tip:
Unlike some other languages, where break and continue are
special syntax that applies only to loops, in Tcl even they are just ordinary
commands! They use Tcl’s very powerful and general exception mechanism to
indicate special conditions to the loop command. You will learn more about other
exceptions in Section 3.4, and how to create your own exceptions
and even your own loop commands in Chapter 7. These and other
capabilities allow you to design programming interfaces that look and behave
just like the built-in commands, creating ‘little languages’ that are
specialised to a particular problem domain or application. Such
domain-specific languages, or
DSLs, are a powerful way of structuring complex software, and Tcl excels at
them. We’ll encounter more examples of this approach in later sections, and
show how you can build your own.
|
3.2.4 The foreach Loop
The foreach loop at first glance appears to be much more limited than the other loops we have discussed. It’s purpose is to simplify iterating over the elements of a list (Section 2.3) in order:
| foreach varName list body |
puts {The authors of "Practical Programming in Tcl/Tk" are:}
foreach x {"Brent Welch" "Ken Jones" "Jeff Hobbs"} {
puts $x
}
The foreach loop is actually much more flexible than the simple version we’ve just presented. It can iterate over multiple lists simultaneously, and it can also extract more than one element from a list at a time. The full syntax is as follows:
| foreach varlist1 list1 ?varlist2 list2 ...? body |
set people {
John 24
Mary 39
Simon 33
}
set salaries {
10000
20000
30000
}
foreach {name age} $people salary $salaries {
puts "$name ($age) earns \$$salary"
}
3.3 Procedures
In Tcl there is actually no distinction between commands (often known as ‘functions’ in other languages), and ‘syntax’. There are no reserved words (like if or while) as exist in C, Java, Python, Perl, etc.. When the Tcl interpreter starts up there is a list of known commands that the interpreter uses to parse a line. These commands include while, for, set, puts, and so on. They are, however, still just regular Tcl commands that obey the same syntax rules as all Tcl commands, both built-in, and those that you create yourself. New commands can be created in a Tcl script using the proc command, short for ‘procedure’. The syntax of this command is as follows:
| proc name params body |
proc sum {x y} {
expr {$x + $y}
}
puts "9 + 13 = [sum 9 13]"
Procedures can be used to package up parts of a script into a new command. This can be used to clearly structure your code into separate functional areas, and also to allow reuse, as the same procedure can be called many times with different arguments from different parts of your program. For instance, imagine we were designing a program to fetch stock quotes from the internet, process them in some manner, and then display them. We could write a single long script that performed each step in turn. However, this would be difficult to read and understand. By using procedures we can break the task up into independent chunks that can be understood in isolation. Our program would then look something like the following:
# Define the parts of our program
proc FetchQuotes {} { ... }
proc Process {quotes} { ... }
proc Display {quotes} { ...}
# Now use them:
set quotes [FetchQuotes]
set processed [Process $quotes]
Display $processed
# Alternatively:
Display [Process [FetchQuotes]]
The only constraint on using procedures is that you must define the procedure before you use it. Some programming languages allow functions to be defined in a later part of the program to where they are used. Tcl forbids this as the proc command needs to have been evaluated to create the procedure before it can be used. One way to get around this is to put the main part of your code into a procedure too, and then call it at the end:
proc Main {} { Display [Process [FetchQuotes]] }
proc FetchQuotes {} { ... }
proc Process {quotes} { ... }
proc Display {quotes} { ... }
# Now call our main procedure
Main
The reason this works is that Tcl doesn’t look inside a procedure body until it is actually called, so the Display and so on procedures are all created by the time the Main procedure is called.
Tip:
As well as making your code easier to read and more structured, procedures in
Tcl also offer a further advantage: speed. The current implementation of Tcl
includes a byte-code compilerin addition to
the standard interpreter. This byte-code compiler can convert Tcl scripts from
simple strings of source-code into a more efficient byte-code format. This
byte-code can then be very efficiently interpreted, resulting in a considerable
speed-up over normal scripts. The use of the byte-code compiler is entirely
hidden to the author of a script: it is just something that the Tcl interpreter
does behind the scenes to improve performance. Traditionally, only code
contained in procedures was sent to the byte-code compiler as this was code that
was likely to be executed multiple times. In more recent Tcl versions, other
code, such as loop bodies, may also be byte-compiled, but it is good style to
put most of your code into procedures, especially if you are targetting older
Tcl versions. The technically-minded can find more details of the byte-code
compiler in [8], which also discusses other important elements of
the current interpreter design.
|
You can actually define procedures with the same name as existing Tcl commands. In this case, Tcl will silently replace the existing command with the new version. This can be useful in certain advanced situations (such as when building a debugger), but can also cause unexpected behaviour. In general you should avoid overwriting standard Tcl commands, or commands from any packages that you use. One simple way to ensure this is to adopt a consistent naming convention for your procedures that is different from the standard naming convention. For example, you could choose to start all of your procedure names with a capital letter, or better yet, use a namespace (Section 4.1).
3.3.1 Parameters and Arguments
In addition to just specifying a name for each parameter, Tcl also allows some parameters to be given a default value. This is done by specifying the parameter as a list of two elements: the name and the default value:
proc sum {x {y 1}} { expr {$x + $y} }
The following sum command can be called with either one or two arguments. If only one argument is given then the y variable will be given the default value of 1, much like in the built-in incr command. Default parameters should only appear after ordinary parameters to avoid confusion as to which argument will be assigned to which parameter.
You can also define commands which take an arbitrary number of arguments. This is done by using the special args parameter name. When this name is used as the name of the last parameter in the parameter list then Tcl will treat that parameter differently. Instead of assigning it a single argument value, it will instead assign it a list of any further arguments that are given. To illustrate:
% proc test {a b args} { puts "a = $a, b = $b, args = {$args}" }
% test 1 2
a = 1, b = 2, args = {}
% test 1 2 3
a = 1, b = 2, args = {3}
% test 1 2 3 4 5 6
a = 1, b = 2, args = {3 4 5 6}
The args parameter can only be the last parameter and it cannot have a default value. The name is not special anywhere else in the parameter list (it will be treated as just an ordinary parameter elsewhere).
3.3.2 Global and Local Variables
As mentioned in the previous section, when a procedure is called, Tcl first creates new variables with the names given in the procedure’s parameter list and assigns them the values of any arguments passed, in order. If the number of arguments doesn’t match the number of parameters then an error will be produced:
% proc sum {x y} { expr {$x + $y} }
% sum 1
wrong # args: should be "sum x y"
Unlike the loop variables used in the for and while commands, variables created inside procedures—either as parameters, or by using the set command—do not continue to exist after the command exits:
% sum 1 2 3 % set x can't read "x": no such variable
In fact, when a procedure is called, Tcl creates a new variable scope that is distinct from the variable scope that we have previously been using. This new variable scope contains only the variables that were created for the parameters. Note that in Tcl only variables defined within a procedure, or explicitly imported (as described later), are visible to the body of the procedure. This is in contrast to some other languages in which variables defined outside of a procedure are also visible. If you wish to make use of a variable defined outside of a procedure, you can import it using the global command4:
proc foo {} {
global x
puts "x = $x"
incr x
}
set x 12
foo
puts "Now, x = $x" ;# displays "Now, x = 13"
Another way of referring to global variables within a procedure is by using a fully-qualified variable name. This is done by prefixing the variable name with two colon characters, ::. This tells Tcl that the variable being referred to is a global variable:
proc foo {} {
puts "x = $::x"
incr ::x
}
In both cases, the variable being referred to doesn’t have to exist when it is referred to: you can also create global variables from within a procedure, using the usual set command:
proc initialise {} {
global name lang
set name "John Ousterhout"
set lang "Tcl"
}
initialise
puts "$name invented $lang!"
The info vars command, introduced in Section 1.3 can be used to get a list of all the variables that are visible in a procedure, either local variables (that have been defined in the procedure), or those that have been imported. You can list just the local variables with the info locals command, and you can list all global variables with the info globals command.
3.3.3 The return Command
A procedure usually returns the value of the last command that executed in that procedure. You can force a procedure to return a specific value by using the return command. In its most basic form, this command takes a single value argument. When executed it will cause the current procedure to exit, returning the value as its result:
proc test a {
if {$a > 10} { return "big" }
return "small"
}
The return command can actually do much more than simply returning a result, as it is the basis of Tcl’s exception mechanism. See Section 3.4.3.3 for details.
3.3.4 The Procedure Call Stack
Each time you call a procedure, a new variable scope is created, and when that procedure returns, the scope is destroyed, destroying any variables that were created inside it. Two calls to the same procedure will result in two separate variable scopes being created. If the body of one procedure calls another procedure then another new variable scope is created and pushed on top of the previous one. When that procedure returns its scope is destroyed and the previous scope on this stack is reinstated. As with global variables, you can also import variables that have been defined in other procedures that are on the stack: a form of explicit dynamic scoping. To do this, you use the upvar command that creates a new local variable that is linked to a local variable defined in another procedure scope. The syntax of the command is:
| upvar ?level? otherVar localVar ?otherVar localVar ...? |
proc foo {} { puts "Here!" }
proc bar {} { foo }
proc jim {} { bar }
jim
At the point at which the ‘Here!’ message is displayed, there will be four frames on the stack, labelled as follows:
| Procedure | Absolute | Relative |
| foo | #3 | 0 |
| bar | #2 | 1 |
| jim | #1 | 2 |
| global | #0 | 3 |
Therefore, in order to import a variable into the foo procedure from it’s caller (in this case, bar), we could use either upvar #2 or upvar 1. Note, though, that we usually cannot be guaranteed that bar will be the only procedure that will call foo, so it is generally bad style to make assumptions about what variables will be available in a particular scope. In fact, most Tcl code only makes use of upvar in a few very limited situations. The most important of these is to mimick the pass-by-reference style of calling available in some other languages. In this style, we explicitly pass a reference to a variable in one scope as an argument to another procedure which then manipulates that variable using upvar. For instance, we can write our own version of the incr command that doubles the variable as follows:
proc double varName {
upvar 1 $varName n
set n [expr {$n * 2}]
}
set x 12
double x
puts "x = $x" ;# displays "x = 24"
The upvar command is almost always used with a level of 0, 1 or #0 in real code. If you find yourself using other levels frequently then it may indicate a design problem, and your code may be difficult to read later on. Generally, good Tcl style is to avoid the use of global variables as much as possible.
As with global, the upvar command can also be used to create variables. The info level command can be used to examine the procedure call stack at runtime.
3.3.5 Recursion: Looping without loops!
Note: The next few sections cover some relatively advanced material. You may wish to skip ahead to Section 3.4 on a first reading, or if you are short of time.
As well as calling other commands, a procedure may also call itself, either directly or indirectly (via another procedure). Such circular calls are known as recursion, and can be used to implement lots of interesting control logic. For instance, we can implement loops without using any of the loop commands by just using procedure calls:
proc count {i end} {
if {$i > $end} { return }
puts "i = $i"
count [expr {$i + 1}]
}
count 1 10
This example prints the numbers from 1 to 10, just like our earlier examples with for and while, but without using an explicit loop. While recursion can be difficult to grasp, especially for problems that have a simple solution using an iterative for loop, many problems can often be concisely expressed using recursive procedures, including many mathematical inductive definitions. For instance, given the following inductive definition of the factorial function (n!), we can easily define a recursive implementation:
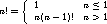
proc fac n {
if {$n <= 1} { return 1 }
if {$n > 1} { expr {$n * [fac [incr n -1]]} }
}
In the case of mathematical functions, we can make this look a bit nicer by making the procedure a function as described in Section 1.5.3:
proc tcl::mathfunc::fac n { ::fac $n }
proc fac n {
if {$n <= 1} { return 1}
if {$n > 1} { expr {$n * fac($n-1)} }
}
Generally, recursive definitions will run slower and use more memory than their iterative counterparts. This is due to the construction and deletion of the stack frames that are needed for each recursive call. From Tcl 8.6, you can use the new tailcall command to convert a recursive definition into an iterative version almost automatically. The tailcall command effectively turns a procedure call into a simple jump: instead of creating a new stack frame, the tailcall command simply reuses the current one for the new procedure. This eliminates the extra memory required for recursive calls as only a single stack frame is required, but it can only appear as the very last operation in a procedure (it is similar to the return command in this regard). This means that our original definition cannot be simply reused, as the recursive call to fac is not the final operation: its result is then used in an expression. Instead, we must add a new accumulator parameter to transform the procedure into tail-recursive form:
proc fac {n {accum 1}} {
if {$n <= 1} { return $accum }
if {$n > 1} { tailcall fac [expr {$n-1}] [expr {$n*$accum}] }
}
The main advantage of the tailcall command is that it enables recursive definitions to run in constant memory space, and to avoid running out of stack memory (which can happen if you try to create too many stack frames). Try both recursive definitions of fac with an argument of 1000: the first will error, whereas the second will produce the correct result.
While the tailcall command solves the problem of memory usage for recursive functions, procedures using it will still run more slowly than their iterative counterparts. Most recursive procedures can be naturally rewritten into an iterative form, using for or while. For example:
proc fac n {
for {set accum 1} {$n > 1} {incr n -1} {
set accum [expr {$accum*$n}]
}
return $accum
}
This version also uses constant space, but runs much quicker than the recursive definitions. Notice how this version also uses an accumulator parameter, but here it is used as the loop variable, rather than as an extra argument.
3.3.6 Higher-Order Procedures and Callbacks
All of the procedures we have seen so far have taken simple string values as arguments. As Tcl procedures are commands, and commands have string names, we can also pass the name of a procedure as an argument to a command. Commands in Tcl are therefore first-class: i.e., they can be treated just like other values in the language, with the caveat that you are always passing the name of a command, rather than the command itself. This means that we can write procedures that take other procedures and commands as arguments. Such procedures are known as higher-order procedures in Computer Science.5 We have already seen some examples of ‘higher-order’ commands, such as the lsort command, which can take a -command option. For instance, we can sort a list of strings by size using the following approach:
proc comp-len {a b} { expr {[string length $a] - [string length $b]} }
lsort -command comp-len $strings
Here the comp-len (‘compare length’) procedure is being passed as an argument to the lsort command. Many other Tcl commands also work in this manner. The comp-len argument is sometimes referred to as a ‘callback command’, or just ‘callback’, as a frequent use of such arguments is to allow a command to ‘call back’ or notify the application when something interesting happens.
As well as supplying some examples of higher-order commands, Tcl also makes it very simple to write your own. Such procedures are very useful for packaging up commonly-used patterns of code (‘design patterns’) into reuseable commands. For example, when processing lists a common operation is to iterate through each element of the list applying some function and building up a new list as we go. For instance, we may want to extract the names from a list of people (where each person is represented as a dictionary):
set people [list {name Neil age 28} {name Mary age 37}]
proc name {record} { dict get $record name }
foreach person $people { lappend names [name $person] }
puts $names ;# displays "Neil Mary"
We can use the same pattern to get the ages, or addresses, and so on. The code is mostly identical, with just a different operation being applied to each element to extract the appropriate field. We can package up this pattern of code into a reuseable procedure, map 6:
proc map {f xs} {
set result [list]
foreach x $xs { lappend result [{*}$f $x] }
return $result
}
This procedure takes a command f and a list xs and then applies the
command to each element of the list, returning a list of the results. The
{*} operator is used to expand the command before we call it, so that we
can pass in commands such as string length and Tcl will know to look for
the length subcommand of the string command, rather than for a
(non-existent) ‘string length’ command. We can use this to implement
our original loop in very little code:
set names [map name $people]
If we expand the definition of map by replacing the arguments with their values, we can see that this performs exactly the same loop as before:
# Expanded definition of map: $f = "name"
set result [list]
foreach x $people { lappend result [name $x] }
The advantage of this style of coding is that we can then re-use this map procedure for selecting other elements, or indeed for completely unrelated tasks:
proc age person { dict get $person age }
set ages [map age $people]
proc plus {a b} { expr {$a + $b} }
set future-ages [map {plus 10} $ages]
Other common higher-order operations on lists include filtering a list to select just those that satisfy some predicate condition:
proc filter {p xs} {
set result [list]
foreach x $xs { if {[{*}$p $x]} { lappend result $x } }
return $result
}
proc less-than {amount x} { expr {$x < $amount} }
filter {less-than 30} $ages
A particularly useful operation is known as a ‘fold’ or ‘reduce’ operation. This operation takes a list of data and folds an operator between each pair of elements:
![[tutorial-Z-G-3.gif]](tutorial-Z-G-3.gif)
As well as specifying the operator to apply, we can also specify a ‘zero’ or ‘identity’ value that is used when the list is empty. We name the procedure foldl to indicate that this version is ‘left-associative’, i.e., that it calculates the result from left-to-right (((1 + 2) + 3) + ...):
proc foldl {f z xs} {
foreach x $xs { set z [{*}$f $z $x] }
return $z
}
We can use this for instance to provide general sum and product operations on lists of integers:
proc + {a b} { expr {$a + $b} }
proc * {a b} { expr {$a * $b} }
proc sum xs { foldl + 0 $xs }
proc product xs { foldl * 1 $xs }
sum {1 2 3 4 5} ;# results in 15
A foldr command can be defined similarly, and is a useful exercise (hint: you may wish to use a for loop instead of foreach). We can even use this definition to write our factorial example! First, we define a helper procedure for generating all natural numbers from 1 up to a given limit (giving it a cute name):
proc 1.. n {
set range [list]
for {set i 1} {$i <= $n} {incr i} { lappend range $i }
return $range
}
We can then simply define the factorial function as the product of all integers from 1..n:
proc fac n { product [1.. $n] }
This definition is as efficient as the iterative version, as it reduces to just a pair of iterative loops, yet it is clearer even than the original recursive definition.7 The main remaining inefficiency is that it must generate the complete list of integers up to n before computing the result. We can eliminate this inefficiency by creating a specialised version of fold especially for operating on integer ranges, n..m8:
proc fold-range {f z n m} {
for {set i $n} {$i <= $m} {incr i} {
set z [{*}$f $z $i]
}
return $z
}
proc fac n { fold-range * 1 1 $n }
3.3.7 Anonymous Procedures
Since Tcl version 8.5
In addition to creating named procedures, Tcl also allows you to create un-named anonymous procedures (sometimes referred to as ‘lambdas’ after the anonymous functions of the Lambda Calculus). An anonymous procedure in Tcl is simply a list consisting of two elements9: a parameter list and a procedure body. These take exactly the same form as they do for normal procedures. As an anonymous procedure has no command name, you cannot call it directly. Instead, it can be called with the apply command:
| apply anonymousProc ?arg ...? |
set plus {{x y} { expr {$x + $y} }}
apply $plus 3 4 ;# returns 7
Many standard Tcl commands that take callbacks will also accept anonymous procedures. The reason for this is that these commands actually accept command prefixes—a list consisting of a command name followed by some initial arguments. Any further arguments are then appended to this command prefix before it is called as a command (recall that a command in Tcl is a list of words). We can pass an anonymous procedure to these commands by making a list consisting of the command name apply followed by our anonymous procedure. For example, we can sort a list by string length in a single command using an anonymous procedure:
lsort -command {apply {{a b} {
expr {[string length $a] - [string length $b]}
}}} $strings
Such in-line anonymous procedures can be useful for short procedures, as they keep the logic of the callback in the same place in the source-code as it is used. For longer procedures, it is still generally better to use a named procedure, so long as you choose a descriptive name. We can make the use of the anonymous procedure easier to read by using a constructor function. This is simply a procedure that constructs some data (in this case, another procedure) and returns it. We will call our anonymous procedure constructor ‘lambda’ in honour of similar constructs in other languages:
proc lambda {params body} { list apply [list $params $body] }
lsort -command [lambda {a b} {
expr {[string length $a] - [string length $b]}
}] $strings
It is generally good style to always use a constructor function for complex data like anonymous procedures. You can even define specialised constructors that use different behaviour. For instance, here is a version that uses the expr command to evaluate the body of the procedure (see if you can work out how it works):
proc func {params body} { list apply [list $params [list expr $body]] }
set plus [func {x y} {$x + $y}]
The higher-order procedures given in Section 3.3.6 will all
work with anonymous procedures, due to the use of the {*} operator:
proc fac n { fold-range [func {x y} {$x * $y}] 1 1 $n }
set future_ages [map [func x { $x + 10 }] $ages]
3.3.8 Command Aliases
Tcl also provides a way to convert a command prefix (i.e., a command name plus a list of initial arguments) into a new named command, using the interp alias command. In basic usage, the syntax is as follows:
| interp alias {} newCommand {} oldCommand ?arg ...? |
{} arguments can be ignored for now—they are explained in
Section 7.4. This command creates a new command called
newCommand, which, when called, will immediately call oldCommand
passing any initial arguments defined in the alias, followed by any other
arguments passed in this call. For example, we can define a sumRange
command that sums all of the integers in a given range, using our previous
fold-range command, as follows:
proc plus {x y} { expr {$x + $y} }
interp alias {} sumRange {} fold-range plus 0
sumRange 1 5 ;# returns 15
When this command is called, the alias is expanded as follows:
sumRange 1 5 => fold-range plus 0 1 5 => 15
Command aliases can be used to convert anonymous procedures back into named procedures:
interp alias {} add {} apply {{x y} { expr {$x + $y} }}
Indeed, with these components we can even define our own version of the proc command!
proc myproc {name params body} {
interp alias {} $name {} apply [list $params $body]
}
myproc add {x y} { expr {$x + $y} }
This new myproc command acts virtually identically to the built-in proc command. This should give you some indication of the flexibility of Tcl, and we have just started to scratch the surface!
3.3.9 Examining Procedures
As for variables, Tcl provides methods for listing the procedures (and other commands) that are defined in the interpreter, through the info command. The info commands and info procs commands can be used to get a list of all commands (including procedures), and just procedures, respectively:
| info commands ?pattern? |
| info procs ?pattern? |
Beyond just listing the names of defined procedures, you can also examine their definitions, using the info args, info default, and info body commands, which return the argument (parameter) list, the default values of any arguments, and the body of a procedure, respectively:
| info args procName |
| info default procName param varName |
| info body procName |
The info default command doesn’t directly return the default value, but
instead returns 1 or 0 to indicate whether the argument has a default value, and
then sets the given variable varName to the default value, if it exists.
This allows you to determine whether a default value has been specified, even if
it is the empty string (""). To illustrate how to use these commands,
here is a small procedure that can recreate the source-code of any procedure
defined in an interpreter (inspired by the functionality in the tkcon
application):
# dump -- dumps the source code of a procedure
proc dump procName {
set body [info body $procName]
set params [list]
foreach param [info args $procName] {
if {[info default $procName $param default]} {
lappend params [list $param $default]
} else {
lappend params [list $param]
}
}
return [list proc $procName $params $body]
}
Entering this into an interactive interpreter session and then running it on itself (i.e., dump dump) results in the same source code being displayed. Such a procedure is a useful tool when developing procedures interactively and debugging.
3.4 Dealing with Errors
Up until now, the Tcl programs we have shown have all assumed that every command succeeds without problems. In the real world, however, things are rarely that simple: a file doesn’t exist, or a network connection cannot be made, or an input that should have been a number turns out to be a name. These are just some examples of the sorts of errors that can occur in everyday programs. Whenever Tcl encounters an error it reacts by generating an error condition, or exception. If any procedures are currently executing, then by default, Tcl will immediately cause them to terminate one-by-one, unwinding the call stack until the top level is reached. At this point an error message is printed. If Tcl is running in interactive mode, you are then presented with the familiar prompt and can continue entering commands. If Tcl was processing a script file, then the interpreter will exit and additionally print a stack traceshowing the procedures that were active at the time of the call. For instance:
proc a {} { b }
proc b {} { c }
proc c {} { d }
proc d {} { some_command }
a
When executed, this script will produce the following error:
invalid command name "some_command"
while executing
"some_command "
(procedure "d" line 1)
invoked from within
"d "
(procedure "c" line 1)
invoked from within
"c "
(procedure "b" line 1)
invoked from within
"b "
(procedure "a" line 1)
invoked from within
"a"
This stack trace is built up as the call stack is unwound, and is additionally recorded in the errorInfo global variable. You can print the contents of this variable from the Tcl interactive prompt to help with debugging errors. In addition to this stack trace, a Tcl error also produces two additional pieces of information:
A simple string message that describes the error in human-readable terms.
An ‘error code’, which is a list designed to be easily processed by a Tcl script (an exception handler). For example, a divide-by-zero error in expr results in an error code of {ARITH DIVZERO {divide by zero}}. The first element gives the general class of error (ARITHmetic), and subsequent elements give more specific details. The error code of an error is available in the errorCode global variable.
3.4.1 The try Command
Since Tcl version 8.6
Tcl also allows a script to intercept error exceptions before they completely unwind the call stack. The programmer can then decide what to do about the error and act accordingly, instead of having the entire application come to a halt. Dealing with errors appropriately is an important part of writing robust software. In fact, Tcl offers two commands for handling errors: the newer try command, and an older catch command. The try command is simpler to use for most cases, whereas the catch command can provide more flexibility in certain circumstances. Most new code should use the newer try command, unless you have very complex requirements or need to support Tcl versions prior to 8.6.
The syntax of the try command is as follows:
| try body ?handler ...? ?finally script? |
| trap pattern varList script |
- pattern:
- A pattern used to match against the error code of the
error. The pattern can specify the full error code, or any prefix of it. For
instance, we can trap all arithmetic errors by using the pattern ARITH.
An empty list (
{}) will match all errors. - varList:
- A list of variables to contain information about the error. The list takes the following format: ?msgVar? ?detailVar?. The first element, if specified, names a variable into which to copy the human-readable error message of the error. The second element names a variable into which to copy the additional detail of the error, in the form of a dictionary value (see Section 2.4), the elements of which are shown below.
- script:
- A script to run if an error matches this pattern. The script will be run in the same variable scope that the try command was originally called from. Any variables defined in that scope, including those specified in the varList are visible. Note that at this point the main body script of the try command has exited, along with any procedures it may have called.
More than one trap clause may be specified in a single try command. When an error is detected, each clause will be tried in the order they are specified until one matches the error code. If no clauses match then the error is propagated as if it had never been caught. If more than one clause matches the error, then only the first in the list will be executed.
Once an error has been trapped, the associated script can perform actions to either recover from the error, or to simply record it and carry on. Typical actions might include logging the error and then ignoring it, or returning a default value. The result of the handler script becomes the new result of the try command. Any errors that occur within the error handler script itself are treated as normal errors: in particular, they are not handled by the error handlers in that try command, but they may be caught by other try commands either within the error handler, or defined in scopes that are still on the call stack.
To illustrate how to use the try command, here is a function that performs integer division on two numbers, x and y, i.e., x/y. In the case when y is zero, this would result in a divide-by-zero error. In this example, we convert such errors into a default value of 0:
proc div {x y} {
try {
expr {$x/$y}
} trap {ARITH DIVZERO} {} {
return 0
}
}
Of course, we could have achieved the same thing in this case by testing the value of y before performing the division, but in many cases errors are not so simple to prevent.
3.4.1.1 Error Options Dictionary
If both variable names are given in a trap clause of the try command, then the second will be filled with a special value called the error options dictionary. This is a dictionary value consisting of a series of attributes and associated values that give extra information about the error that occurred. The keys available in the options dictionary are as follows:
- -errorcode:
- Contains the full error code of the error, as also found in the errorCode global variable.
- -errorinfo:
- Contains the stack trace of the error up to this point, as found in the errorInfo global variable.
- -errorline:
- An integer indicating which line of the original script passed to the try command was executing when the error occurred.
Two other keys are also available: -code and -level. These will be discussed later, in Section 3.4.1.3. The values of each of these attributes can be extracted using the dict get command, described in Section 2.4. Here is an example procedure that shows some information about any errors that occur within a script:
proc show-error script {
try $script trap {} {msg opts} {
puts "Error: $msg"
puts " Code: [dict get $opts -errorcode]"
puts " Line: [dict get $opts -errorline]"
puts "Stack:"
puts [dict get $opts -errorinfo]
}
}
For example, here is the output from a script that produces a divide-by-zero error:
% show-error { expr {1/0} }
Error: divide by zero
Code: ARITH DIVZERO {divide by zero}
Line: 1
Stack:
divide by zero
invoked from within
"expr {1/0} "
("try" body line 1)
3.4.1.2 The finally Clause
In addition to catching errors, the try command also allows you to specify a script that will be run regardless of if any errors occur or not. This is the purpose of the finally clause. The finally clause can be used to clean up any resources that were acquired prior to the try command being executed. The script supplied to a finally clause will be run after the main body script, and after any error handlers have run. It will always be run, even if an error handler itself produces an error. This is very useful for guaranteeing that certain actions always get performed no matter what happens (short of the Tcl interpreter terminating). For example, we can write a procedure to read and return the contents of a file, and guarantee that if the file is opened at all, it will always be closed before the procedure returns10:
proc readfile file {
set in [open $file]
try { read $in } finally { close $in }
}
The finally clause in this example ensures that the file is always closed after its contents have been read, regardless of any errors that may occur in the process. These errors are still passed on to the caller of the readfile command, but they do not prevent the file being closed.
3.4.1.3 Other Exceptions
As well as handling errors, the try command can also catch other types of exceptions. In Section 3.2.3 we explained that the break and continue commands were also types of exceptions. The return command of Section 3.3.3 is another type of exception! The try command can handle all of these types of exceptions, and any more that might be defined. This is done using a different clause in the list of exception handlers:
| on code varList script |
| ||||||||||||||||
| Table 4: Tcl exception codes | ||||||||||||||||
Catching non-error exceptions is mostly useful in the context of defining custom control structures, such as new loops. These uses are discussed in Section 7.1.
3.4.2 The catch Command
In older versions of Tcl, the only way to catch errors and exceptions was with the simple catch command. This command will catch all exceptions (including normal/ok completion) that are raised in the script it is given, returning the code of the exception and optionally setting variables to contain the message/result and options dictionary of the exception:
| catch script ?resultVar? ?optionsVar? |
proc div {x y} {
set code [catch { expr {$x / $y} } result options]
if {$code == 1} {
# An error occurred
set errorcode [dict get $options -errorcode]
if {[string match {ARITH DIVZERO *} $errorcode]} { return 0 }
}
return -options $options $result
}
This example is harder to understand than the equivalent with try.
3.4.3 Throwing Errors and Exceptions
Tcl scripts can throw their own exceptions using one of three separate commands: throw, error, and return.
3.4.3.1 The throw Command
Since Tcl version 8.6
The throw command takes the following form:
| throw errorcode message |
throw {ARITH DIVZERO {divide by zero}} "divide by zero"
3.4.3.2 The error Command
The error command is similar to the throw command:
| error message ?errorinfo? ?errorcode? |
proc throw {code message} { error $message "" $code }
3.4.3.3 Throwing Other Exceptions
The most general method of throwing an exception is to use the return command, which is the Swiss Army Knife of exception generation. In addition to simply returning a result, return can also generate any exception, and specify values for the options dictionary. The full syntax of return is as follows:
| return ?-option value ...? ?result? |
- -code:
- Specifies an exception code for a new exception to be generated. Can be one of: ok, return, error, break, continue or an integer code.
- -errorcode:
- Specifies the error code for a new exception.
- -errorinfo:
- Specifies the stack trace for a new exception.
- -level:
- Specifies how many levels of the call stack to unwind before generating the exception. This defaults to 1, which means that the current procedure scope will be executed before the exception is generated. A value of 2 would cause the caller of this procedure to also exit, and so on.
- -options:
- Allows specifying the complete options dictionary for the new exception.
Note that return -code error and error are not the same, as the former causes the current procedure to exit before the error is generated, whereas the latter immediately generates the error. The latter behaviour can be achieved by specifying a -level 0 argument to the return, or by wrapping the return in a separate procedure:
proc myError msg { return -code error $msg }
proc myThrow {code msg} {
return -code error -errorcode $code $msg
}
The return command is also useful in error handlers when you wish to re-throw an exception that could not be handled:
try {
...
} trap SOME_ERROR {msg opts} {
...
return -options $opts $msg
}
1 In earlier versions of Tcl, glob-matching was the default, so it is good to get into the habit of always specifying what sort of matching you require.
2 It is conventional to name loop variables as i or j. Any name could be used, but experienced programmers will recognise i and j as loop variables.
3 The commands for reading files are covered in more detail in Chapter 5
4 Variables defined at the top level of a script are known as global variables, and the top level itself is known as the global scope.
5 The origin of this term is in mathematical logic. You might like to think of higher-order commands as being a bit like adverbs in natural languages such as English.
6 Named after the same function in functional programming languages.
7 See http://www.willamette.edu/~fruehr/haskell/evolution.html for a humourous look at the many ways of defining the factorial function.
8 Another way of removing this inefficiency would be to use a lazy list or stream that only computes its elements as they are needed. Such an extension is left as an exercise for the curious reader.
9 A third element is also permitted: a namespace. See Section 4.1.
10 The commands for reading the file are described in Chapter 5.